通常我們不會每個 model 都進行 save,而是設定幾次存一次 Model ,在 PyTorch 中,你可以使用 torch.save 函數來保存模型的狀態字典(state_dict)。這是保存模型的推薦方法。以下是保存模型的範例:
每個epoch都會抓N個batch去訓練Model,其中這邊的一個iteration就代表抓一個batch去訓練Model
https://github.com/fan84sunny/T2I-Adapter/blob/7056c7fb080afc55ce246b2e8b5d0488977fc72f/train_seg.py#L318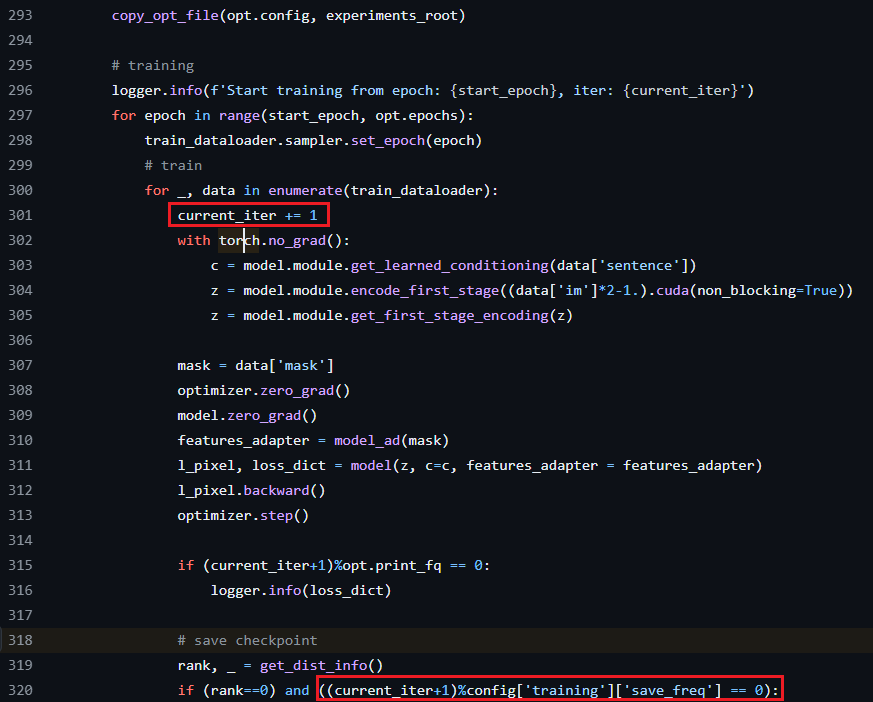
所以在設定幾個iteration去存model一次? config['training']['save_freq']在哪裡?
https://github.com/fan84sunny/T2I-Adapter/blob/main/train_seg.py#L206
config = OmegaConf.load(f"{opt.config}")
# 這邊是自己下指令時才會自動去抓你下的config是用哪個?
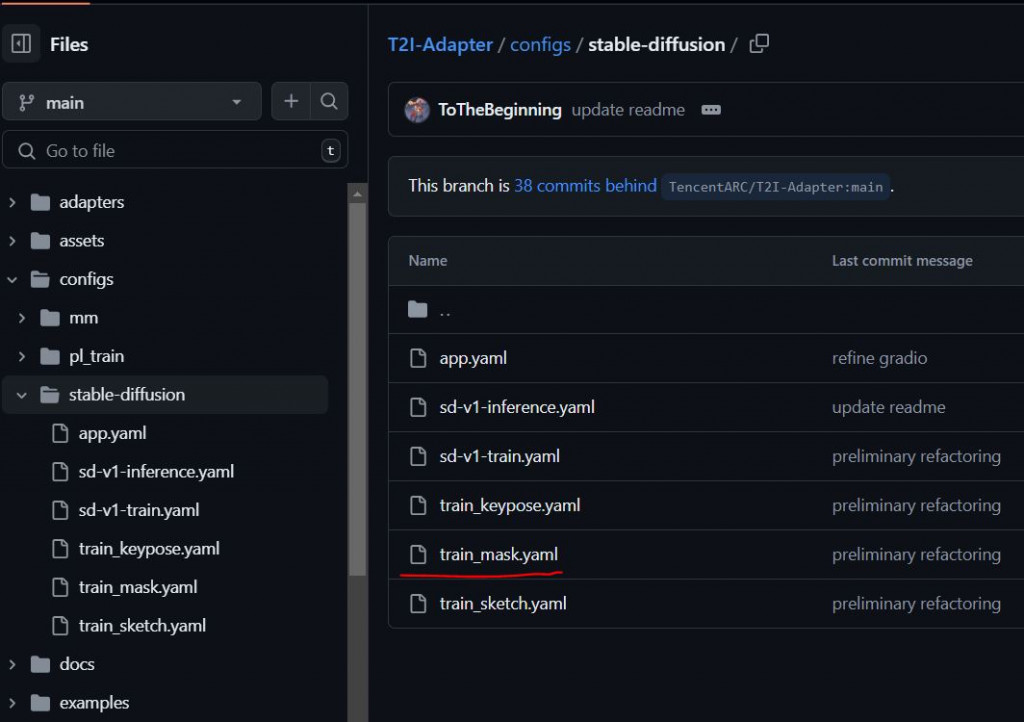
config['training']['save_freq'] = 1e4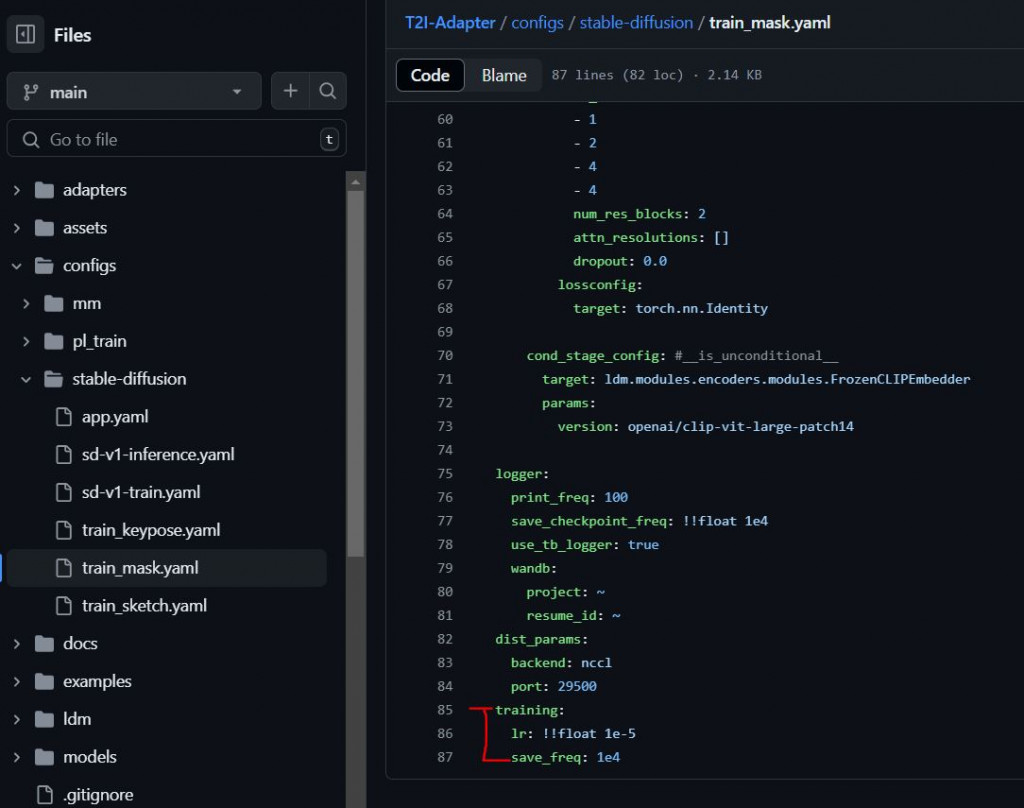
OmegaConf他會去抓yaml的階層,有階層關係,所以才會變成['training']['save_freq']
# 假設你有一個模型叫做 model
model_ad = ... # 你的模型定義
# 提取出原始模型
model_ad_bare = get_bare_model(model_ad)
https://github.com/fan84sunny/T2I-Adapter/blob/main/train_seg.py#L324
這段程式碼的目的是從包裝的模型中提取出原始模型。當你使用 DataParallel 或 DistributedDataParallel 來進行多 GPU 訓練時,模型會被包裝在這些類中。這樣做的原因是為了在多個 GPU 上分配和同步模型的參數。
然而,有時候你可能需要訪問原始的模型(即未包裝的模型),例如在保存模型或進行某些操作時。這段程式碼的 get_bare_model 函數就是為了這個目的而設計的。
以下是這段程式碼的詳細解釋:
目的是在保存模型的狀態字典(state_dict)時,移除多餘的 .module 前綴。當你使用 DataParallel 或 DistributedDataParallel 進行多 GPU 訓練時,模型的參數名稱會自動加上 .module 前綴。這段程式碼會移除這個前綴,然後將參數保存到一個新的字典中,並最終保存到指定的路徑。
檢查模型是否被包裝:
.module,所以要改掉避免loading只能在多GPU環境上面運行。DataParallel 或 DistributedDataParallel 包裝。如果是,則提取出原始模型(即 net.module)。if isinstance(net, (DataParallel, DistributedDataParallel)):
net = net.module
這樣做的好處是,你可以在不使用多 GPU 訓練的情況下,方便地載入和使用這些模型參數。
# 保存模型的狀態字典
torch.save(model.state_dict(), 'model.pth')
# 因為原本訓練在 GPU 上面,要改成cpu 如果環境中只有CPU的狀況下才不會出問題
save_dict[key] = param.cpu()
torch.save(save_dict, save_path)
https://github.com/fan84sunny/T2I-Adapter/blob/main/train_seg.py#L267
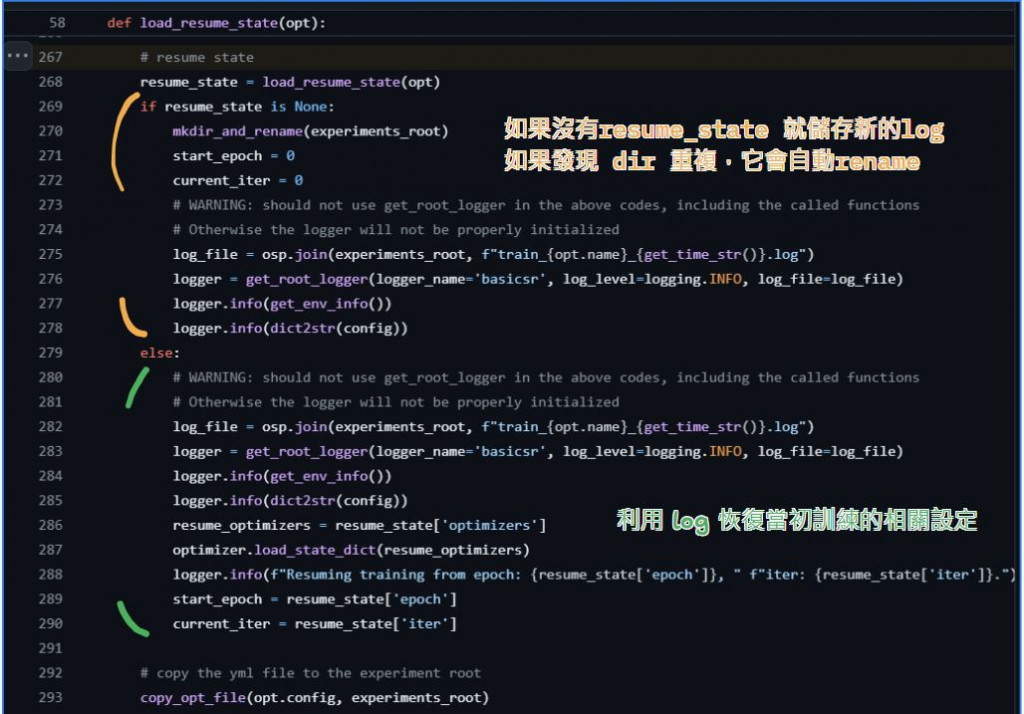
我很少使用到這個
這段程式碼的目的是在訓練過程中自動恢復模型的狀態,包括模型參數、優化器狀態和訓練進度。讓我們逐步解釋這段程式碼:
如果 opt.auto_resume 為真,則檢查 experiments 目錄下是否存在訓練狀態文件。如果存在,則找到最新的狀態文件並設置 resume_state_path。
if opt.auto_resume:
state_path = osp.join('experiments', opt.name, 'training_states')
if osp.isdir(state_path):
states = list(scandir(state_path, suffix='state', recursive=False, full_path=False))
if len(states) != 0:
states = [float(v.split('.state')[0]) for v in states]
resume_state_path = osp.join(state_path, f'{max(states):.0f}.state')
opt.resume_state_path = resume_state_path
state_path = osp.join('experiments', opt.name, 'training_states') 要確定 這個資料夾底下 有.state的文件。scandir 函數列出目錄中所有以 .state 為後綴的文件,並將結果存儲在 states 列表中。states = [float(v.split('.state')[0]) for v in states]: 將每個狀態文件名中的數字部分提取出來,並轉換為浮點數。例如,'123.state' 會被轉換為 123.0。
因為這個數字是iteration,要給訓練提取 iteration 到哪裡了
if opt.auto_resume:
state_path = osp.join('experiments', opt.name, 'training_states')
if osp.isdir(state_path):
states = list(scandir(state_path, suffix='state', recursive=False, full_path=False))
if len(states) != 0:
states = [float(v.split('.state')[0]) for v in states]
resume_state_path = osp.join(state_path, f'{max(states):.0f}.state')
opt.resume_state_path = resume_state_path
直接載入權重就好,不要管其他設定
因為基本上應該不會動...
# 創建一個新的模型實例
adapter_model = Adapter()
# 載入保存的狀態字典
adapter_model.load_state_dict(torch.load('adapter_model.pth'))
在這篇文章中,我們探討了多個與模型訓練和保存相關的主題,並詳細解釋了如何在 PyTorch 中保存和載入模型。我們首先介紹了如何使用 torch.save 和 torch.load 函數來保存和載入模型的狀態字典,並提供了完整的範例代碼。接著,我們討論了如何從包裝的模型中提取出原始模型,這在使用 DataParallel 或 DistributedDataParallel 進行多 GPU 訓練時尤為重要。
我們還深入分析了如何在訓練過程中自動恢復模型的狀態,包括模型參數、優化器狀態和訓練進度。通過檢查目錄中的狀態文件並找到最新的狀態文件,我們可以方便地從上次中斷的地方繼續訓練,這對於長時間訓練的模型特別有用。
這些技巧和方法可以幫助我們更有效地管理和恢復模型的訓練狀態,從而提高訓練效率和模型性能。


 iThome鐵人賽
iThome鐵人賽